Introduction
I am trying to setup a Deep Q-Learning agent. I have looked that the papers Playing Atari with Deep Reinforcement Learning as well as Deep Recurrent Q-Learning for Partially Observable MDPs as well as looking at the question How does LSTM in deep reinforcement learning differ from experience replay?.
Current setup
I currently take the current state of a game, not picture but rather the position of the agent, the way the agent is facing and some inventory items. I currently only feed state $S_t$ as at input to a 3 layer NN (1 input, 2 hidden, 3 output) to estimate the Q-values of each action.
The algorithm that I use is almost the same as the one used in Playing Atari with Deep Reinforcement Learning, with the only difference that I do not train after each timestep but rather sample mini_batch*T at the end of each episode and train on that. Where T is the number of time-steps in that episode.
The issue
At the current state, the agent do not learn within 100 00 episodes, which is about 100 00 * 512 training iterations. Making me consider that something is not working, this is where I realised that I do not consider any of the history of the previous steps.
What I currently struggle with is sending multiple time-steps-states to the NN. The reason for this is the complexity of how the game/program I am using. According to Deep Recurrent Q-Learning for Partially Observable MDPs LSTM could be a solution for this, however I would prefer to manually code a RNN rather than using an LSTM. Would not a RNN with something like the following structure have a chance of working?
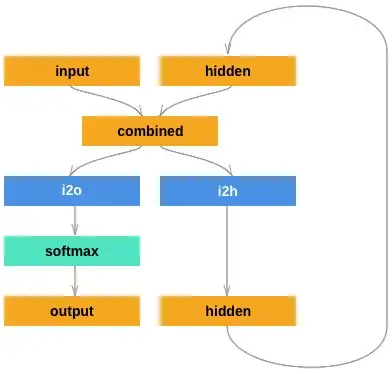
Also, as far as I know, RNN need the inputs to be fed in sequence and not randomly sampled?