I have been working on some RL project, where the policy is controlling the robot using its joint angles.Throughout the project I have noticed some phenomenon, which caught my attention. I have decided to create a very simplified script to investigate the problem. There it goes:
The environment
There is a robot, with two rotational joints, so 2 degrees of freedom. This means its continuous action space (joint rotation angle) has a dimensionality of 2. Let's denote this action vector by a. I vary the maximum joint rotation angle per step from 11 to 1 degrees and make sure that the environment is allowed to do a reasonable amounts of steps before the episode is forced to terminate on time-out.
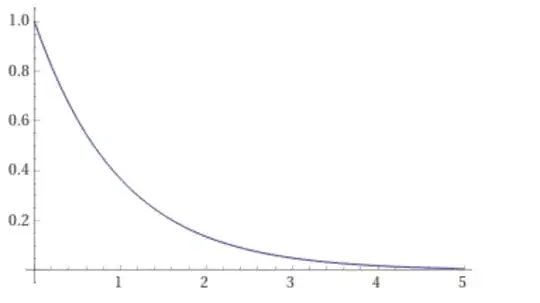
Our goal is to move the robot by getting its current joint configuration c closer to the goal joint angle configuration g (also two dimensional input vector). Hence, the reward I have chosen is e^(-L2_distance(c, g)).
The smaller the L2_distance, the exponentially higher the reward, so I am sure that the robot is properly incentivised to reach the goal quickly.
Reward function (y-axis: reward, x-axis: L2 distance):
So the pseudocode for every step goes like:
move the joints by predicted joint angle delta
collect the reward
if time-out or joint deviates too much into some unrealistic configuration: terminate.
Very simple environment, not to have too many moving parts in our problem.
RL algorithm
I use Catalyst framework to train my agent in the actor-critic setting using TD3 algorithm. By using a tested framework, which I am quite familiar with, I am quite sure that there are no implementational bugs.
The policy is goal-driven so the actor consumes the concatenated current and goal joint configuration a= policy([c,g])
The big question
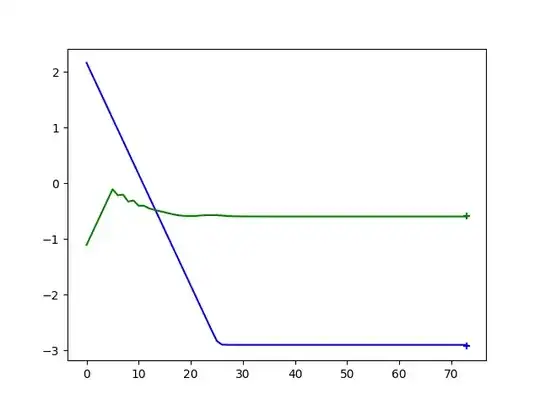
When the robot has only two degrees of freedom, the training quickly converges and the robots learns to solve the task with high accuracy (final L2 distance smaller than 0.01).
Performance of the converged 2D agent. y-axis: joint angle value, x-axis: no of episodes. Crosses denote the desired goal state of the robot.:
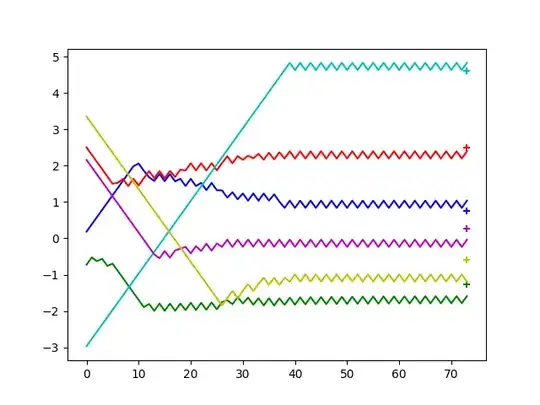
However, if the problem gets more complicated - I increase the joint dimensions to 4D or 6D, the robot initially learns to approach the target, but it never "fine-tunes" its movement. Some joints tend to oscillate around the end-point, some of them tend to overshoot.
I have been experimenting with different ideas: making the network wider and deeper, changing the action step. I have not tried optimizer scheduling yet. No matter how many samples the agent receives or how long it trains, it never learns to approach targets with required degree of accuracy (L2_distance smaller than 0.05).
Performance of the converged 4D agent. y-axis: joint angle value, x-axis: no of episodes. Crosses denote the desired goal state of the robot.:
Training curve for 2D agent (red) and 4D agent (orange). 2D agent quickly minimises the L2 distance to something smaller than 0.05, while the 4D agent struggles to go below 0.1.:
Literature research
I have looked into papers which describe motion planning in joint space using TD3 algorithm.
There are not many differences from my approach: Link 1 Link 2
Their problem is much more difficult because the policy needs to also learn the model of the obstacles in joint space, not only the notion of the goal. The only thing which is special about them is that they use quite wide and shallow networks. But this is the only peculiar thing. I am really interested, what do you guys would advise me to do, so that the robot can reach high accuracy in higher joint configuration dimensions? What am I missing here?!
Thanks for any help in that matter!