I am following a course on machine learning and am confused about the bias-variance trade-off relationship to learning curves in classification.
I am seeing some conflicting information online on this.
The scikit-learn learning curve looks like the top 2 curves here: 
(source: scikit-learn.org)
{kind=link}
What I don't understand is: how do we read bias from this? If we look at this image where each blue dot is a model. I think the bias would be the green curve being high. But high bias indicates underfitting, right? So shouldn't the red curve be high then too?
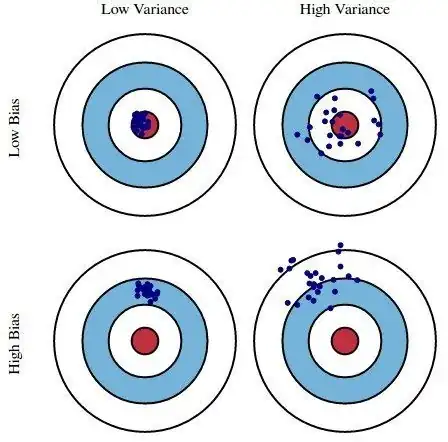
High variance would be the gap between green and red, is this correct?
My question is how do the red and green curves relate to underfitting and overfitting, and how do learning curves fit with the figure with the concentric circles? Is bias purely related to the red curve, or is a model with a low validation score and high train score also a high bias model?