SO the YOLO V3 and RetinaNet both uses the Feature pyramids which look something like this: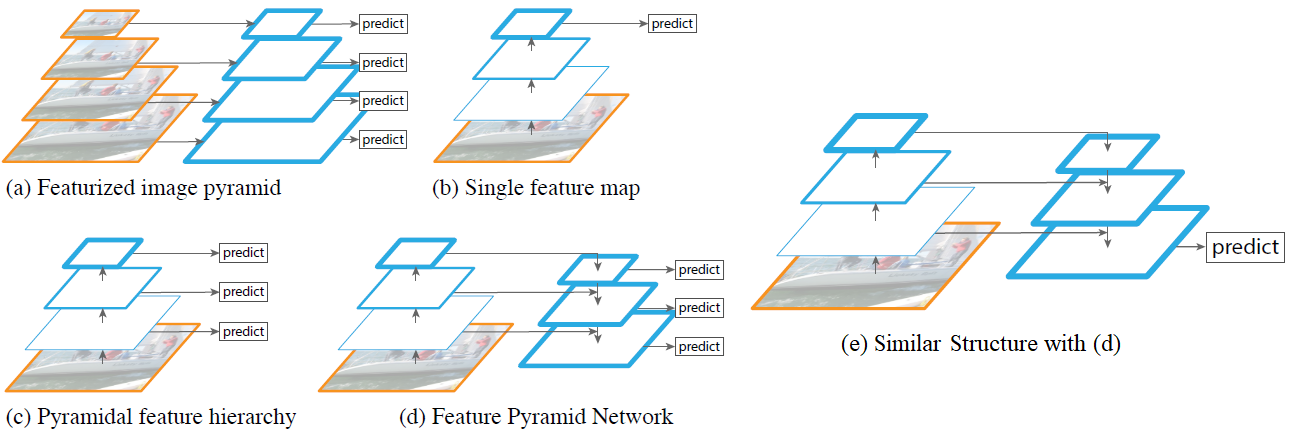 (except
(except b and e which have one output)
I'm just confuse how the predictions and training is done?
Do we have to give EACH feature map a different Y label? IF yes, how is that possible? We need to have N different ground truth in my opinion. (Also ther'll be 3 different losses I think?)
If not, then how are these done at once?
There is a lot of confusion on these networks because I am not able to get my head around How are y-labels provided, trained and predicted in YOLOv3 and RetinaNet . Everything will make sense about loss, multioutputs and all if I know this one thing.