I am currently experimenting with the U-Net. I am doing semantic segmentation on the 2018 Data Science Bowl dataset from Kaggle without any data augmentation.
In my experiments, I am trying different hyper-parameters, like using Adam, mini-batch GD (MBGD), and batch normalization. Interestingly, all models with BN and/or Adam improve, while models without BN and with MBGD do not.
How could this be explained? If it is due to the internal covariate shift, the Adam models without BN should not improve either, right?
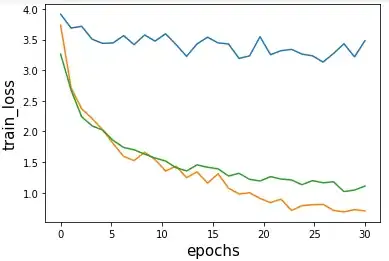
In the image below is the binary CE (BCE) train loss of my three models where the basic U-Net is blue, the basic U-Net with BN after every convolution is green, and the basic U-Net with Adam instead of MBGD is orange. The learning rate used in all models is 0.0001. I have also used other learning rates with worse results.