There are several key differences between YOLOv3 and RetinaNet.
RetinaNet is an object detection model that utilizes two-stage cascade and sampling heuristics to address class imbalance during training. whereas YOLOv3 is a real-time, single-stage object detection model that builds on YOLOv2 with several improvements.
RetinaNet uses a ResNet50 backbone, while YOLOv3 uses a Darknet53 backbone.
RetinaNet uses Focal Loss to prevent the easy background examples from overwhelming the network during training, while YOLOv3 uses Cross-Entropy loss.
YOLOv3 is fast and accurate in terms of mean average precision (mAP) and intersection over union (IOU) values as well.
YOLOv3 predicts bounding boxes and class probabilities directly from full images in a single pass, while RetinaNet first classifies proposal regions and then predicts bounding boxes and class probabilities for each region. This makes YOLOv3 faster and simpler, but also less accurate than RetinaNet. hence suitable for use where the priority is real-time performance with FPS: 51. RetinaNet has a high mAP 82.89%, but the detection speed FPS: 17 is not fast enough for real-time application.
The accuracy of detecting objects with YOLOv3 can be made equal to the accuracy when using RetinaNet by having a larger dataset, making it an ideal option for models that can be trained with large datasets.
The loss function of YOLOv3 converges faster, indicating that the training time of the YOLOv3 model is shorter than RetinaNet.
RetinaNet is better at detecting rotated objects.
YOLOv3 can be trained on more data more quickly than RetinaNet
The loss functions used by each algorithm are different.
YOLOv3 may not be ideal for using niche models where large datasets can be hard to obtain but its sutible for models like traffic detection, where plenty of data can be used to train the model since the number of images of different vehicles is plentiful.
Precision for Small Objects:
The chart below (taken and modified from the YOLOv3 paper) shows the average precision (AP) of detecting small, medium, and large images with various algorithms and backbones. The higher the AP, the more accurate it is for that variable.
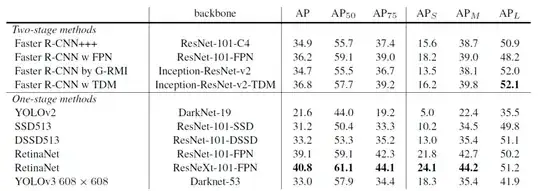
Source: Focal Loss for Dense Object Detection
YOLOv3 increased the AP for small objects by 13.3, which is a massive advance from YOLOv2. However, the average precision (AP) for all objects (small, medium, large) is still less than RetinaNet.
Speed:
YOLOv3 is fast and accurate in terms of mean average precision (mAP) and intersection over union (IOU) values as well. It runs significantly faster than other detection methods with comparable performance (hence the name – You only look once). Moreover, you can easily trade off between speed and accuracy simply by changing the model’s size, without the need for model retraining.
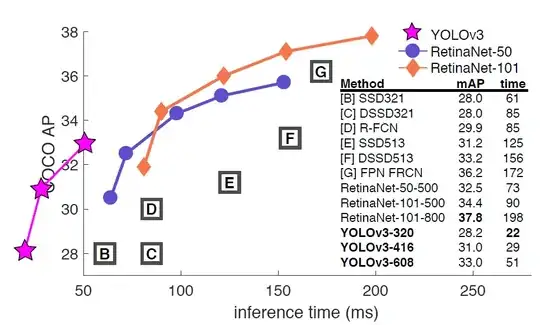
References:
RetinaNet(PapersWithCode)
YOLOv3(PapersWithCode)
Comparison of RetinaNet, SSD, and YOLO v3 for real-time pill identification
A Practical Guide to Object Detection using the Popular YOLO Framework – Part III (with Python codes)
Object Detection for Dummies Part 3: R-CNN Family
Comparison of YOLOv3 and SSD Algorithms

