Does deep learning assume that the fitness landscape on which the gradient descent occurs is a smooth one?
One can interpret this question from a formal-mathematical standpoint and from a more "intuitively-practical" standpoint.
From the formal point of view, smoothness is the requirement that the function is continuous with continuous first derivatives. And this assumption is quite often not true in lots of applications - mostly because of the widespread use of ReLU activation function - it is not differentiable at zero.
From the practical point of view, though, by "smoothness" we mean that the function's "landscape" does not have a lot of sharp jumps and edges like that:
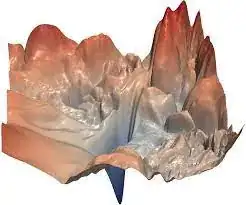
Practically, there's not much difference between having a discontinuous derivative and having derivatives making very sharp jumps.
And again, the answer is no - the loss function landscape is extremely spiky with lots of sharp edges - the picture above is an example of an actual loss function landscape.
But... why the gradient descent works then?
As far as I know, this is a subject of an ongoing discussion in the community. There are different takes and some conflicting viewpoints that are still subject of a debate.
My opinion is that, fundamentally, the idea that we need it to converge to the global optimum is a flawed one. Neural networks was shown to have enough capacity to completely remember the training dataset. A neural network, that completely remembered the training data. has reached the global optimization minimum (given only the training data). We are not interested in such overtrained models - we want models that generalize well.
As far as I know, there is no conclusive results on which properties of the minimum are linked to ability to generalize. People argued that these should be the "flat" minima, but then it was refuted. After that a "wide optimium" term was introduced and gave rise of an interesting technique of Stochastic Weight Averaging.
