another question in YOLO. I've red about how YOLO adjusts anchor boxes by offsets to create the final bounding boxes. What I do not understand, is when YOLO does it. Is it being done only during the training process, or also during the common use of already trained model?
Asked
Active
Viewed 361 times
1 Answers
2
Object detection models behave the same during both, training and test phase, i.e. they just return thousands and thousands of bounding boxes as predictions, plus a confidence score for each box (important). What change between training and test is what we make out of these bounding boxes.
Trainining:
During training we want to assess how good each bounding box is with respect to our ground truth annotations, so what happen is usually a brutal comparison between each predicted bounding box with each true annotation box. Of course we need to quantify the quality of each predicted box vs true annotation, we can do that using Intersection Over the Union(IOU), i.e. percentage of shared pixels between the total area of the two boxes combined. We don't care during training about the amount of predictions the model return, we just want the model to learn to predict good boxes on overall.
Test:
During test instead we want indeed to have a single box per object, but the model is still returning thousands of them, so we need to find a way to select one ourselves, and this is why the predicted confidence scores are important, otherwise we would have no idea about what boxes are better than others. The most common algorithm used to choose winning boxes depending on their confidence scores is called Non Maximum Suppression.
The picture below shows the algorithm (taken from the linked blog post).
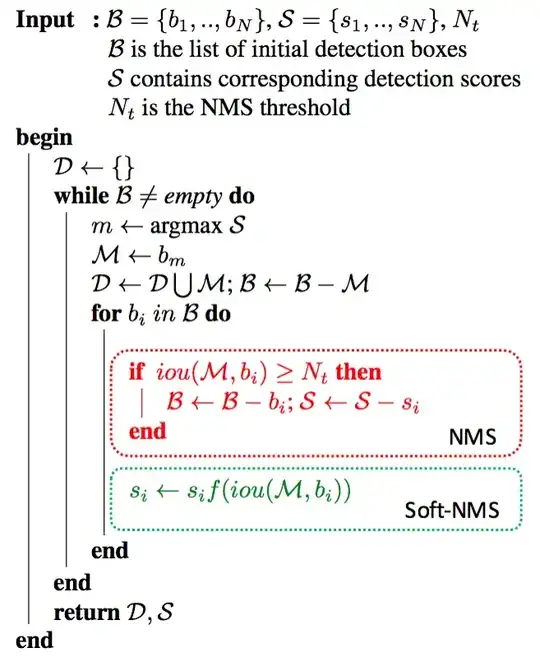
You can see that Non-Max Suppression work iteratively, starting from the box with highest confidence score, and checking the IOU between it and the remaining boxes. In order to work, an initial threshold parameter needs to be set, this threshold is used to determine if one of the remaining boxes should be kept and tested in the next iteration or not. Basically we want to discard boxes that overlap too much. Conceptually, if I have a box with high confidence score in a location, and another box overlapping a lot with it but with a lower confidence score, I want to keep only the first one and discard the second. If instead two boxes are not overlapping, then they might be detecting different objects, and I want to keep both. Notice that in a soft version of Non-Max Suppression the IOU score is used to update the confidence scores of each box as well. After converging, Non-Max Suppression will return the set of best non overlapping boxes.
Edoardo Guerriero
- 5,153
- 1
- 11
- 25
-
maybe I missed the point. I understand what you say sir, but it seems to me not exactly an answer to what I have asked. My question is about the ancor boxes. A am sure they are used to train a model on a dataset as they are being apposed to the ground truth boxes (backpropagation process adjustes them untill they fit to the location and size of ground truth boxes). But I doubt that they are used in a common daily use of already trained yolo model. Am i right? – Igor Feb 03 '22 at 11:29