If you have up-to 100 objects in a single image, their size must be fairly small percentage-wise. let's say their diameter is 50 pixels and the whole image is 1024 x 1024. Are the objects always non-overlapping, thus somewhat far apart? If so, you could label the known objects with a mask value of 1, their nearby pixels are set to a mask value of 0, and everything else is set to 0.5. Let's call this "Mask A".
Now you construct a normal CNN which maps a 1024 x 1024 x 1 image to a mask of the same size. But the network takes a second input as well: "Mask B". This is calculated as Mask B = (Mask A != 0.5), meaning that indicates to which pixels we know the correct answer (either 0 or 1). The network's output is modified so that it outputs the normal values where Mask B is true, and 0.5 to pixels where Mask B is false. The binary cross-entropy is calculated against the Mask A which has values 0, 0.5 and 1.
Note that regardless of the model's parameters, it will always output a value of 0.5 to those pixels which are also 0.5 at Mask A. Thus they won't contribute to the loss or its derivatives.
I did a simple network in Keras and trained it with simulated data:
inputs = [layers.Input((res,res,1)) for _ in range(2)]
x = inputs[0]
for dim in [8, 16, 8, 4, 1]:
x = BN()(layers.Conv2D(dim, 7, activation='elu', padding='same')(x))
x = layers.Conv2D(1, 11, padding='same', activation='tanh')(x)
x = (x * inputs[1] + 1) * 0.5
model = keras.Model(inputs, x)
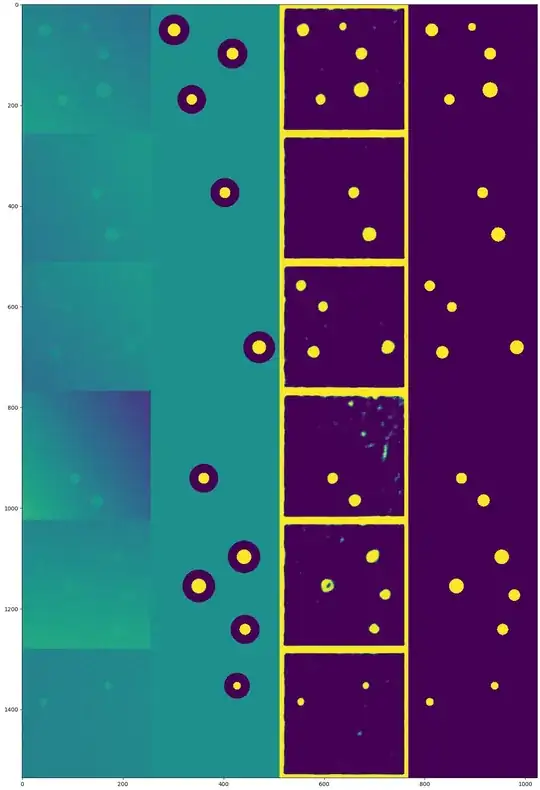
Note that tanh was used instead of sigmoid, since it made the "hard-code unknown pixels as 0.5" a bit easier. The generated dataset consists of grayscale images (shown left), partially labeled data (yellow = known circle, dark blue = known non-circle and blue-green for unlabeled pixels), the network's output and the ground-truth. The network is able to find all the circles quite well, but there are some false positives and the border seems to be labeled all ones.
But this approach cannot be used if the objects could overlap, and we cannot generate a sufficiently large "neighbourhood region" around it with known labels of "no object".
