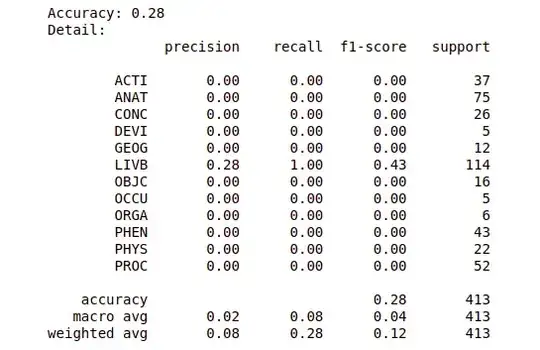
Despite how software might work, neural networks do not return labels. Neural networks return probabilities of class membership (typically fairly poor ones, which is a topic for a separate question). If you make probability predictions instead of having your software tell you the most probable category, I expect you to find that you have more diversity in those predictions than “LIVB every time”.
What’s happening is that LIVB is the most likely category going into the problem, and you need considerable evidence to shake your prior belief that LIVB is the most likely outcome. You are unable to produce enough evidence for another category to shake the mode away from giving LIVB the highest probability. Thus, this seems to be a matter of bias: your model lacks the ability to strongly discriminate between categories and tends to fall back on its prior probability that LIVB is most likely.
Annoyingly, it might be that this is just how your problem works: LIVB might always be the most likely outcome.
Finally, I agree with other comments that there are too few observations for a neural network to have much of a shot of being useful. Neural networks are a great way to get a lot of discriminative ability in order to get the model to scream, “This is not LIVB!” However, you probably lack the data needed for a large network not to overfit.