There are six different situations:
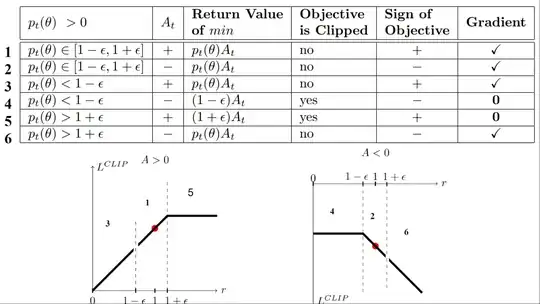
Case 1 and 2: the ratio is between the range
In situations 1 and 2, the clipping does not apply since the ratio is between the range $[1 - \epsilon, 1 + \epsilon]$
In situation 1, we have a positive advantage: the action is better than the average of all the actions in that state. Therefore, we should encourage our current policy to increase the probability of taking that action in that state.
Since the ratio is between intervals, we can increase our policy’s probability of taking that action at that state.
In situation 2, we have a negative advantage: the action is worse than the average of all actions at that state. Therefore, we should discourage our current policy from taking that action in that state.
Since the ratio is between intervals, ** the probability that our policy takes that action at that state**
Case 3 and 4: the ratio is below the range
If the probability ratio is lower than $[1 - \epsilon]$, the probability of taking that action at that state is much lower than with the old policy.
If, like in situation 3, the advantage estimate is positive ($A>0$), then you want to increase the probability of taking that action at that state.
But if, like situation 4, the advantage estimate is negative, we don’t want to decrease further the probability of taking that action at that state. Therefore, the gradient is = 0 (since we’re on a flat line), so we don’t update our weights.
Case 5 and 6: the ratio is above the range
If the probability ratio is higher than $[1 + \epsilon]$, the probability of taking that action at that state in the current policy is much higher than in the former policy.
If, like in situation 5, the advantage is positive, we don’t want to get too greedy. We already have a higher probability of taking that action at that state than the former policy. Therefore, the gradient is = 0 (since we’re on a flat line), so we don’t update our weights.
If, like in situation 6, the advantage is negative, we want to decrease the probability of taking that action at that state.
So if we recap, we only update the policy with the unclipped objective part. When the minimum is the clipped objective part, we don’t update our policy weights since the gradient will equal 0.
Source: DEEP RL Course - Visualize the Clipped Surrogate Objective Function


