How are the layers in a encoder connected across the network for normal encoders and auto-encoders? In general, what is the difference between encoders and auto-encoders?
Asked
Active
Viewed 1,734 times
3 Answers
8
Theory
Encoder
- In general, an Encoder is a mapping $f : X \rightarrow Y $ with $X$ Input Space and $Y$ Code Space
- In case of Neural Networks, it is a Generative Model hence a function which is able to compute a Representation out of some input (like GAN)
The point is: how would you train such an encoder network ?
- The general answer is: it depends on what you want your code to be and ultimately depends on what kind of problem the NN has to solve, so let's pick one
Signal Compression
The goal is to learn a compressed representation for your input that allows to reconstruct the original input minimizing the loss of information
In this case hence you want the dimensionality of $Y$ to be lower than the dimensionality $X$ which in the NN case means the code space will be represented by less neurons than the input space
Autoencoder
Focusing on the Signal Compression problem, what we want to build is a system which is able to
take a given signal with size
Nbytescompress it into another signal with size
M<Nbytesreconstruct the original signal, starting from the compressed representation, as good as possible
To be able to achiebve this goal, we need basically 2 components
an Encoder which compresses its input, performing the $f : X \rightarrow Y$ mapping
a Decoder which decompresses its input, performing the $f: Y \rightarrow X$ mapping
We can approach this problem with the Neural Network Framework, defining an Encoder NN and a Decoder NN and training them
It is important to observe this kind of problem can be effectively approached with the convenient learning strategy of unsupervised learning : there is no need to spend any human work (expensive) to build a supervision signal as the original input can be used for this purpose
This means we have to build a NN which operates essentially between 2 spaces
the $X$ Input Space
the $Y$ Latent or Compressed Space
The general idea behind the training is to make a certain input go along the encoder + decoder pipeline and then compare the reconstruction result with the original input with some kind of loss function
To define this idea a bit more formally
- The final autoencoder mapping is $f : X \rightarrow Y \rightarrow X$ with
- the $x$ input
- the $y$ encoded input or latent representation of the input
- the $\hat x$ reconstructed input
- Eventually you will get an architecture similar to
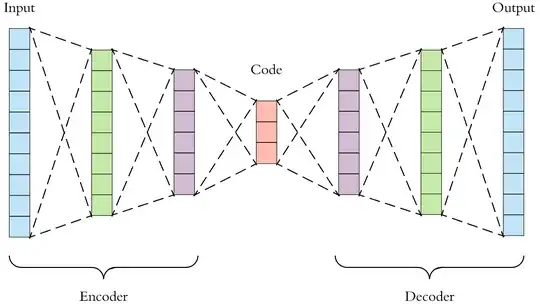
- You can train this architecture in an unsupervised way, using a loss function like $f : X \times X \rightarrow \mathbb{R}$ so that $f(x, \hat x)$ is the loss associated to the $\hat x$ reconstruction compared with the $x$ input which is also the ideal result
Code
Now let's add a simple example in Keras related to the MNIST Dataset
from keras.layers import Input, Dense
from keras.models import Model
# Defines spaces sizes
## MNIST 28x28 Input
space_in_size = 28*28
## Latent Space
space_compressed_size = 32
# Defines the Input Tensor
in_img = Input(shape=(space_in_size,))
encoder = Dense(space_compressed_size, activation='relu')(in_img)
decoder = Dense(space_in_size, activation='sigmoid')(encoder)
autoencoder = Model(in_img, decoder)
autoencoder.compile(optimizer='adam', loss='binary_crossentropy')
Nicola Bernini
- 799
- 5
- 12
-
Is binary_crossentropy the correct loss function to use there? Wouldn't mean_squared_error be the better choice? – DrMcCleod Apr 14 '19 at 09:11
-
Binary cross entropy should be a good choice in this specific case of MNIST digits reconstruction, as it is modelled as a per-pixel binary classification: we just want to know what pixels to turn on – Nicola Bernini Apr 14 '19 at 09:34
-
@NicolaBernini can you explain the use of ce loss? Mnist is a grayscale image so how did you convert it to binary? (I have seen this in many places without any explanation) – Apr 14 '19 at 11:59
-
@nicolabernini why wouldn't you be interested in the grayscale values of the decoded image? MNIST pixels are not just on and off. – DrMcCleod Apr 14 '19 at 12:17
-
@DuttaA because the less relevant kind of details is exactly the one related to the original pixel values: what you really want is to turn on the pixels giving you the right digit appearance (instead of defining an appearance which is properly spread across the full grayscale domain) – Nicola Bernini Apr 14 '19 at 13:33
-
@NicolaBernini but how do you decide the threshold? – Apr 14 '19 at 14:08
-
Sorry, I do not understand what you mean: the Sigmoid Activation Th is a learned parameter, not an hyperparam Just to recap, before the actual processing the pixel values get normalized (so they are in the [0..1] range) so you have to classify between 0 (turned off) and 1 (turned on) – Nicola Bernini Apr 14 '19 at 14:13
-
@NicolaBernini yes they are in 0-1 range but not exactly 0 or 1 so how do you decide which pixel gets to be 0 or 1? – Apr 14 '19 at 15:28
-
Try having a look at the per-pixel values PDF in MNIST: you clearly observe 2 strong peaks, one for {0} and the other for {255} That's because the MNIST image is intended to be binary and the you can consider all the other values as noise Normalizing data, the NN predicts a {0,1} class and compares it with the input then evaluates with binary cross entropy – Nicola Bernini Apr 14 '19 at 16:17
1
As an addition to NicolaBernini's answer. Here is a full listing which should work with a Python 3 installation that includes Tensorflow:
"""MNIST autoencoder"""
from tensorflow.python.keras.layers import Input, Dense, Flatten, Reshape
from tensorflow.python.keras.models import Model
keras.datasets import mnist
import matplotlib.pyplot as plt
from matplotlib.pyplot import figure
"""## Load the MNIST dataset"""
(x_train, y_train), (x_test, y_test) = mnist.load_data()
"""## Define the autoencoder model"""
## MNIST 28x28 Input
image_shape = (28,28)
## Latent Space
space_compressed_size = 25
in_img = Input(shape=image_shape)
img = Flatten()(in_img)
encoder = Dense(space_compressed_size, activation='elu')(img)
decoder = Dense(28*28, activation='elu')(encoder)
reshaped = Reshape(image_shape)(decoder)
autoencoder = Model(in_img, reshaped)
autoencoder.compile(optimizer='adam', loss='mean_squared_error')
"""## Train the autoencoder"""
history = autoencoder.fit(x_train, x_train, epochs=10, shuffle=True, validation_data=(x_test, x_test))
"""## Plot the training curves"""
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.legend(['loss', 'val_loss'])
plt.show()
"""## Generate some output images given some input images. This will allow us to see the quality of the reconstruction for the current value of ```space_compressed_size```"""
rebuilt_images = autoencoder.predict([x_test[0:10]])
"""## Plot the reconstructed images and compare them to the originals"""
figure(num=None, figsize=(8, 32), dpi=80, facecolor='w', edgecolor='k')
plot_ref = 0
for i in range(len(rebuilt_images)):
plot_ref += 1
plt.subplot(len(rebuilt_images), 3, plot_ref)
if i==0:
plt.title("Reconstruction")
plt.imshow(rebuilt_images[i].reshape((28,28)), cmap="gray")
plot_ref += 1
plt.subplot(len(rebuilt_images), 3, plot_ref)
if i==0:
plt.title("Original")
plt.imshow(x_test[i].reshape((28,28)), cmap="gray")
plot_ref += 1
plt.subplot(len(rebuilt_images), 3, plot_ref)
if i==0:
plt.title("Error")
plt.imshow(abs(rebuilt_images[i] - x_test[i]).reshape((28,28)), cmap="gray")
plt.show(block=True)
I have changed the loss function of the training optimiser to "mean_squared_error" to capture the grayscale output of the images.
Change the value of
space_compressed_size
to see how that effects the quality of the image reconstructions.
A.Casanova
- 103
- 3
DrMcCleod
- 583
- 4
- 12
1
To answer this rather succinctly, an encoder is a function mapping some input to some different space. An example of this is what the brain does. We have to process the sensory input that the environment gives us in order for it to be storable.
An autoencoder's job, on the other hand, is to learn a representation(encoding). An autoencoder will have the same number of output nodes as there are inputs for the purposes of reconstructing the inputs instead of trying to predict the Y target. Autoencoders are usually used in reducing output dimensions in high dimensional data sets.
Hope I answered your question!
hisairnessag3
- 1,235
- 5
- 15
-
Why would you need to reconstruct the inputs if you already have them? I think you should answer to this question too. – nbro Apr 14 '19 at 10:03