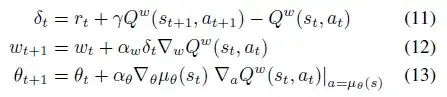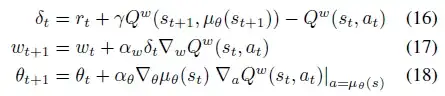In the paper Deterministic Policy Gradient Algorithms, I am really confused about chapter 4.1 and 4.2 which is "On and off-policy Deterministic Actor-Critic".
I don't know what's the difference between two algorithms.
I only noticed that the equation 11 and 16 are different, and the difference is the action part of Q function where is $a_{t+1}$ in equation 11 and $\mu(s_{t+1})$ in equation 16. If that's what really matters, how can I calculate $a_{t+1}$ in equation 11?