As it turns out, I can do it with imagemagick. If you don't have it, install simply with:
sudo apt-get install imagemagick
Note 1:
I've tried this with a one-page pdf (I'm learning to use imagemagick, so I didn't want more trouble than necessary). I don't know if/how it will work with multiple pages, but you can extract one page of interest with pdftk:
pdftk A=myfile.pdf cat A1 output page1.pdf
where you indicate the page number to be split out (in the example above, A1 selects the first page).
Note 2:
The resulting image using this procedure will be a raster.
Open the pdf with the command display, which is part of the imagemagick suite:
display file.pdf
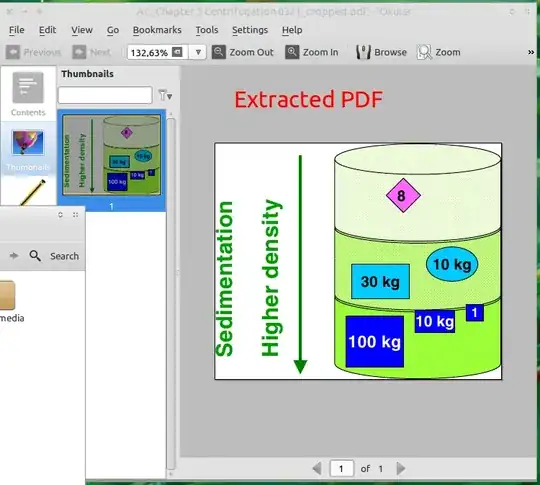
Mine looked like this:

Click on the image to see a full resolution version
Now you click on the window and a menu will pop to the side. There, select Transform | Crop.

Back in the main window, you can select the area you want to crop by simply dragging the pointer (classic corner-to-corner selection).
Notice the hand-shaped pointer around the image while selecting
This selection can be refined before proceeding to the next step.
Once you are done, take notice of the little rectangle that appears on the upper left corner (see the image above). It shows the dimensions of the area selected first (e.g. 281x218) and second the coordinates of the first corner (e.g. +256+215).
Write down the dimensions of the selected area; you'll need it at the moment of saving the cropped image.
Now, back at the pop menu (which now is the specific "crop" menu), click the button Crop.

Finally, once you are satisfied with the results of cropping, click on menu File | Save
Navigate to the folder where you want to save the cropped pdf, type a name, click the button Format, on the "Select image format type" window select PDF and click the button Select. Back on the "Browse and select a file" window, click the button Save.

Before saving, imagemagick will ask to "select page geometry". Here, you type the dimensions of your cropped image, using a simple letter "x" to separate width and height.

Now, you can do all this perfectly from the command line (the command is convert with option -crop) -- surely it's faster, but you would have to know beforehand the coordinates of the image you want to extract. Check man convert and an example in their webpage.








pdftk A=in.pdf cat A1-10 A15 A17 output out.pdf– m8mble Oct 28 '16 at 12:06pdftkis not available in Ubuntu 18.04. (see https://askubuntu.com/questions/1028522/how-can-i-install-pdftk-in-ubuntu-18-04-bionic) – alkamid Jun 30 '18 at 12:05pdftkis certainly a tool that can do the job, I would recommend against it. This is not free software, but an clunky piece of shareware. Also it needs the JVM. A more reasonable tool isqpdf, as suggested in another answer. – leftaroundabout Nov 13 '18 at 13:11pdftk) is free, licensed under GPL: https://www.pdflabs.com/docs/pdftk-license/ – Dario Seidl May 15 '20 at 14:04pdftkin Ubuntu 20.04, I usedsudo apt install pdftk-java. When I tried to runpdftkprior to it being installed, it told me how to install it. I believe it also said something like this would work:snap install pdftk. – Gabriel Staples Dec 24 '20 at 18:11export LD_PRELOAD=/usr/lib/x86_64-linux-gnu/libgtk3-nocsd.so.0. – Hastur Jan 13 '21 at 14:49no Javainstalled insnapnor inapt list, but pdftk works. How is that? – Timo Feb 24 '21 at 15:56Ato address pages, I think it needs to be uppter case, soadoes not work. – Timo Feb 24 '21 at 16:03pdftkbecame open source in 2017, so it is now/again standard in GNU/Linux distributions. "pdftk-java is a port of PDFtk into Java[6] which is developed by Marc Vinyals and GPL licensed. The initial release was on December 30, 2017." (wikipedia). It goes by the simple command line namepdftk. – CPBL Oct 30 '21 at 20:47pdftk A=first.pdf B=second.pdf cat A1-7 B1-5 A8 output combined.pdf. – Asclepius Dec 01 '21 at 14:55