I also do a lot of searching through very large libraries of PDFs. For me, this is the #1 frustration of Linux that makes me miss MS Windows. I've tried it all at this point, and the solution I have settled on for now is to use the following programs in combination.
Unfortunately, none of these seem to be in the Ubuntu repositories at the moment, and may be unstable. So if Recoll (now in the default repository for Ubuntu 14.04 I beleive?) or something else works for you, better to stick with that.
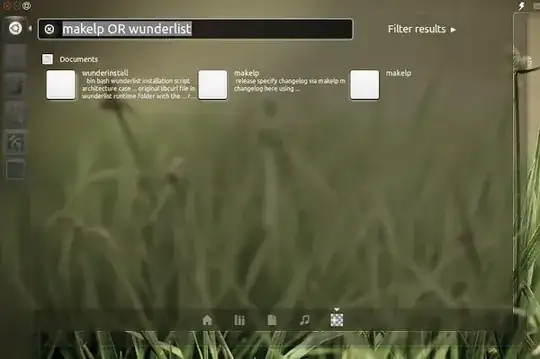
1) Synapse
Installation: Read this post for details, but basically you can install it by running the following commands in a terminal.
sudo apt-add-repository ppa:synapse-core/testing
sudo apt-get update
sudo apt-get install synapse
Positive
- Very fast, smart search results
- If what you want doesn't come up right away, you can press down and tab to find more with "locate".
Negative
- Only searches filenames, not text inside.
- Seems to miss a lot, especially before you try "locate".
2) Launchy
Installation: Download the package here.
Positive:
- Almost as fast as Synapse
- Results are very comprehensive.
Negative:
- Also only searches filenames.
- Probably the buggiest of these three.
3) DocFetcher
Installation: Unless you can find it in a repository somewhere, you are stuck with the portable version. Download it here and follow the instructions.
Positive:
- Searches inside the text of your PDFs
- Comprehensive but relevant results, in a logical order (I usually find the results in Recoll or Tracker to be completely screwy in comparison)
- Full document preview pane so you can see more of the file before you open it (not just a few lines)
- Reasonably fast
Negative:
- Hard to install and run natively in Ubuntu (e.g. without Java runtime)
- Much slower than the apps that only search filenames
Hopefully Dash will catch up and make all of this obsolete, but in the meantime these three are mostly what I am using.
Other options maybe worth trying:
- Gnome-Do might be a worthy alternative to Synapse, but last I checked it can only index 5000 files, and that is not enough for me
- pdfgrep is sometimes useful but slow and has no GUI that I am aware of

 you can also use gnome-search-tool .
you can get it by
you can also use gnome-search-tool .
you can get it by